Production guardrails, one slug away.
Firewall sits before the model. Group rules, pick a mode (signal_only or blocked), and reference the slug in any OpenAI-compatible request.
OpenAI-compatible
response = client.chat.completions.create(
model="your-model",
messages=[{"role": "user", "content": prompt}],
extra_body={"firewall_slug": "production-guardrails"},
)
See the request path before the model sees anything.
The firewall evaluates every request before inference starts. Unsafe input stops at the boundary. Safe input keeps moving.
User
Shopper
Message
f*** you
Firewall
Policy check
blocked
403 returned before inference
Assistant
Model
Response
No response sent
User
Shopper
Message
Hey!
Firewall
Policy check
allowed
Request reaches the model
Assistant
Model
Response
I'm doing well — how can I help?
Two ways to enforce policy.
Warn the model. Let it explain.
The firewall evaluates the request. If it flags something, it tells the model the request is unsafe and instructs it to explain why carefully to the user. The model still responds, but with guardrail context.
Stop unsafe requests before inference.
The firewall evaluates the request. If it flags something, it returns a 403 before the model ever sees it. No compute wasted, no unsafe response possible.
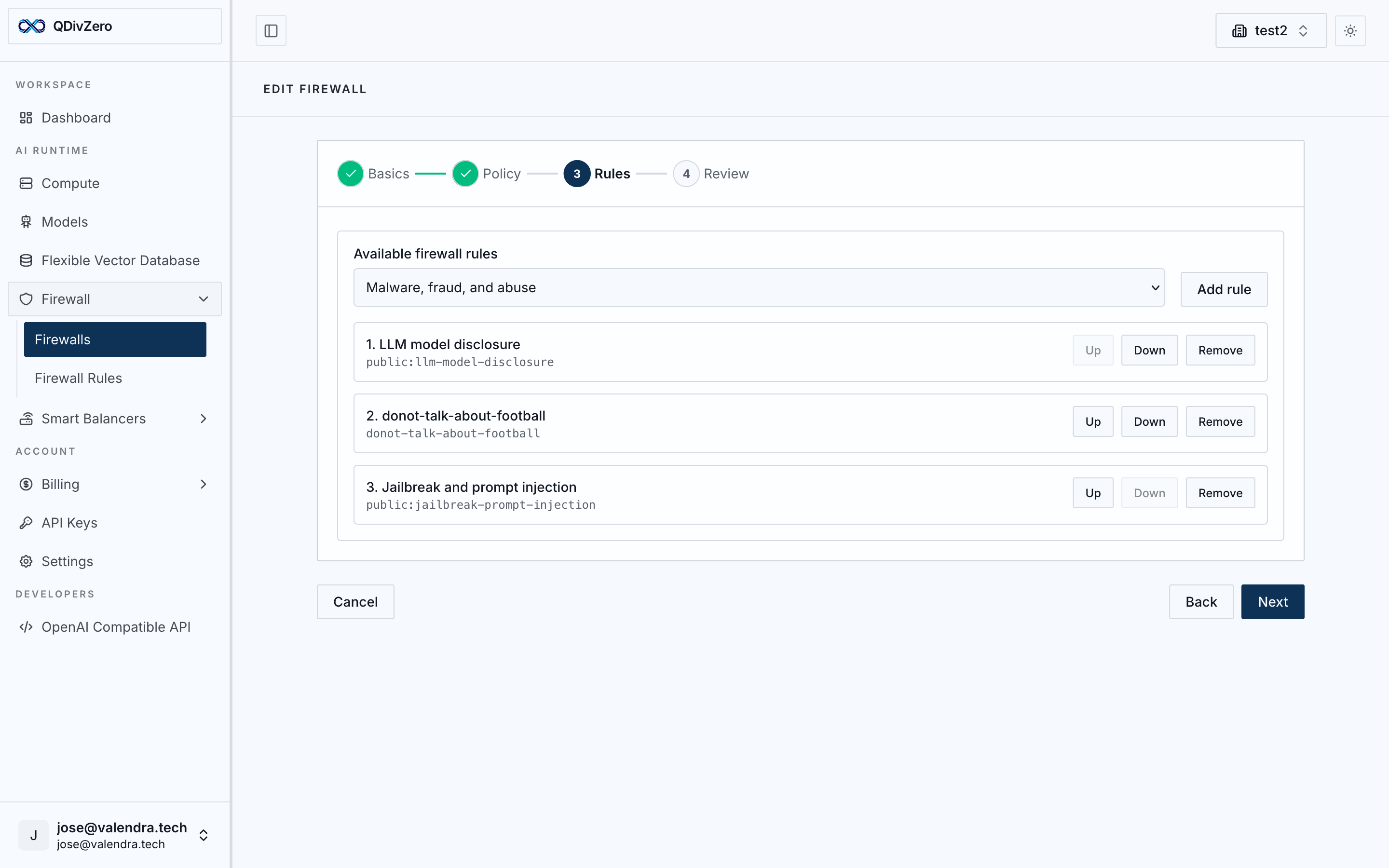
Production rules, maintained for you.
QDivZero ships with seven guardrail rules across safety, privacy, abuse, and security categories. They are updated as threats evolve.
Rule intelligence
1/7abuse
highMalware, fraud, and abuse
public:malware-fraud-abuse
Flags requests about malware, scams, fraud, or abusive misuse.
Your rules, your prompts.
Build rules with your own prompts for what your application needs to filter. Same modes, same API, same enforcement path as built-in rules.
“Don't let the model talk about football.”
Custom rules use the same signal_only or blocked mode as built-in rules. Describe what to catch and the firewall handles the rest.
What Firewall already includes.
Built-in rules
Seven production-maintained guardrail rules.
Custom rules
Define your own policies with prompts.
signal_only mode
Warn the model so it can explain.
blocked mode
Return 403 before inference starts.
OpenAI-compatible
Pass firewall as a request parameter.
Evaluator model
Configurable model that runs the evaluation.
Attach a firewall slug to any request.
Pass a firewall slug to any OpenAI-compatible request. The evaluator runs before the model, and the mode decides what happens next.
View docsfrom openai import OpenAI
client = OpenAI(
base_url="https://api.qdiv0.com/v1",
api_key="your-api-key",
)
response = client.chat.completions.create(
model="your-model",
messages=[
{"role": "user", "content": prompt},
],
extra_body={"firewall_slug": "production-guardrails"},
)Add guardrails to production inference.
Start with Compute, configure a firewall, and keep unwanted questions away from your models.